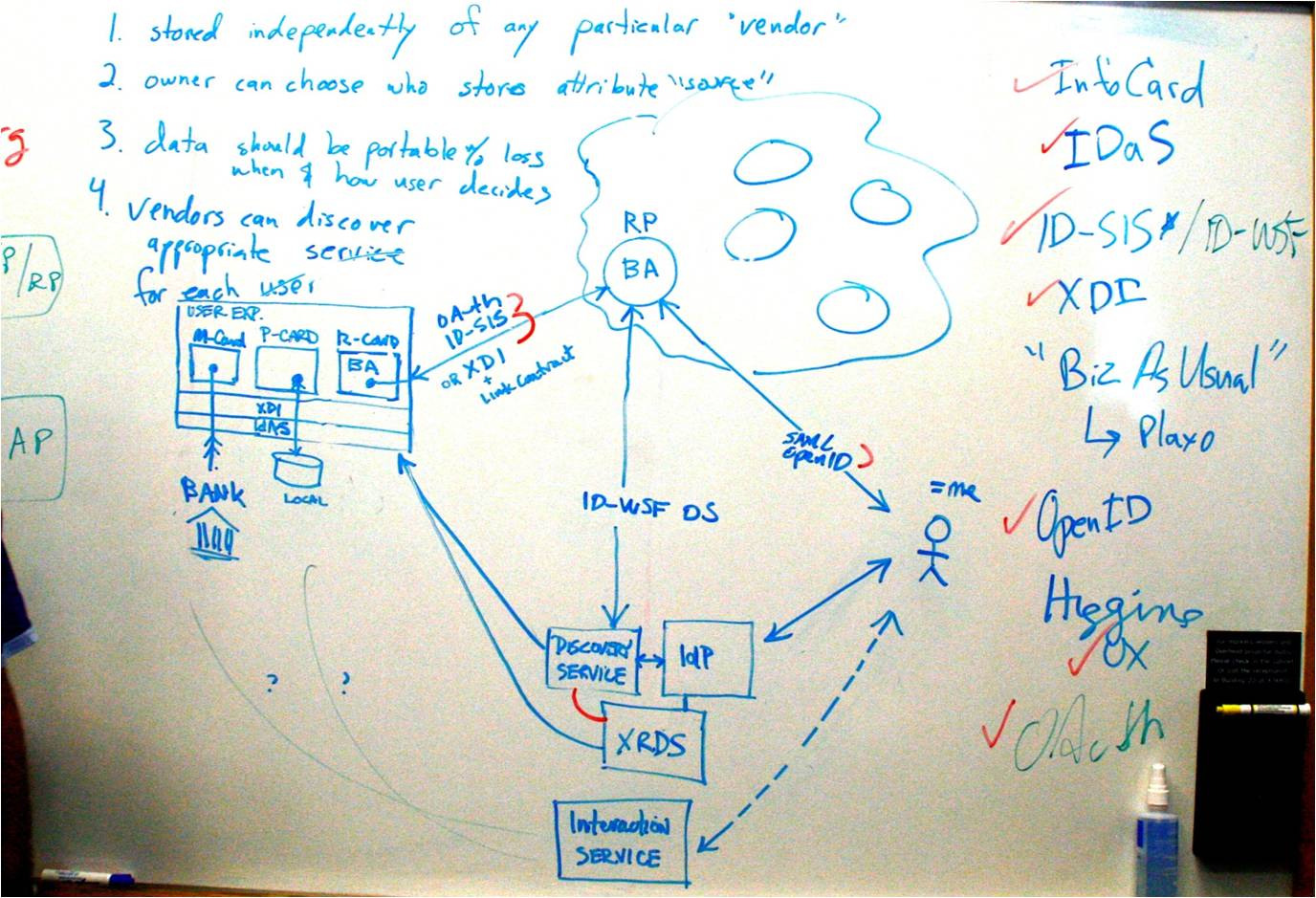
Alex Iskold of Blue Organizer asks “What is the Killer App?” for the Semantic Web in an article that nicely condenses the current best of class in the major contending promises of what Tim Berner’s Lee has recently dubbed the Giant Global Graph:
- Natural Language Understanding
- No longer a need for cryptic “Googlese” to get the computer to give you want you want.
- The Genie in the Bottle
- The magically perfect assistant who can answer any question or satisfy any need you might have.
- Semantic Knowledge Bases
- Semantic Search
- Social Graph
- Shortcuts
- Intra-page shortcuts that augment a web page’s content to enhance a user’s browsing experience. This includes SnapShots from Snap, BlueOrganizer and SmartLinks from Alex’s own AdaptiveBlue, Shortcuts from Yahoo!, and In-text search from Lingospot.
It’s nice walk through the space and particularly interesting how Alex responds to the current state-of-the-art in each. I’ll summarize here, so I can respond in turn (check out the full article for Alex’s actual statements):
- Natural Language Understanding
- Huge, hairy problem. No solution in site.
- The Genie in the Bottle
- Even harder. Needs magic that isn’t even conceptually well understood.
- Semantic Knowledge Bases
- More detailed data is good, but does it really help users? Not emotionally catalytic enough for people to actually get excited and jump on board.
- Semantic Search
- Doesn’t look like the killer app so far, because none of the “semantic” approaches seem to improve much on Google.
- Social Graph
- This is just a subset of the semantic web and therefore not its killer app.
- Shortcuts
- An up and coming category, these embedded shortcuts remove search as the killer navigation online. However, it is still young, misunderstood, and also lacks emotional umph.
First, the most intriguing item is that Alex is candid enough to be critical of the category in which he places his own company’s flagship product. Perhaps AdaptiveBlue has turned the corner on their conceptualization of the market and are rapidly, fiercely developing their next innovation, their next rev, the thing that just might become the killer app of the Semanic Web. That makes me curious, indeed.
Second, I like the break down, but naturally have some slightly different opinions. SwitchBook is still largely in stealth mode–we have yet to publish much on what we are doing even though we are relatively open in face-to-face meetings. However, from my posts here you can guess that it involves search, user-centrism, and particularly the principles underlying VRM.
So let’s look at Alex’s breakdown again:
Natural Language Understanding
Definitely a huge problem. Not only do you have to deal with the incredible elasticity of language, once you’ve mapped the natural language into some sort of internal representation, you still have to figure out what the heck you are going to do with it.
In other words, “understanding” is context specific not just in terms of words having different meaning in different places–Jaguar could mean a car, a cat, or an operating system depending on whose brochure or website you find it on–but it also has different meaning based on what you (as a system, as a service) are going to do with that understanding.
- Are you going to return web pages that contain Jaguar with the same meaning?
- Are you going to offer alternatives to the term Jaguar, like a thesaurus?
- Are you going to translate Jaguar into other languages?
- Are you going to sell Jaguar compatible products?
- Are you going to reason over the threats and opportunities of Jaguars?
All of these require fundamentally different internal representations of the “understanding” of the natural language from the user.
As Jaron Lanier will tell you, language is an interface by which people remotely control the world outside their mind. We use it to communicate with others to get what we want and to understand how to respond to others (which is basically figuring out how to eventually get others to give us what we want). As such, its primary use, its raison-d’etre, is to influence the world around us. So, what we really want isn’t to understand the language, but to understand (1) what a speaker wants and (2) how to influence the world.
It turns out, people are incredibly adaptive at both of these tasks. Language is just one of the interfaces we use and we are capable of learning entirely new tools quickly when they demonstrate a more efficient, more effective way to get what we want. The humble spreadsheet is one of my favorite examples of this. I believe that more people “program” in MS Excel than in any classic programming language: we write mini-programs using functions like sum() and average() and put data in and look at the results. Who would’ve thought that entry-level clerical workers, accountants, and soccer moms around the world would’ve learned to program? And yet, they do. In my opinion, Excel is probably the most widely used programming environment in the corporate world.
Could you imagine trying to replace that with Natural Language? I can only imagine that a natural language version of Excel would be more convoluted and harder to use, but maybe that’s just because I lack imagination.
The Genie in the Bottle
This is more interesting. I agree that this goal is arbitrarily far away–no one will crack this nut entirely until we have both omniscience and omnipotence programmed into our software (and that is essentially never). However, by understanding clearly exactly what the Genie would do if he or she could, then you have a starting point for building innovative solutions.
Consider the development of online virtual worlds. Many people also said that the fictional Star Trek holodeck is arbitrarily far into the future, that, like the Genie, it requires so much advanced technology as to effectively be magic. And yet, Janet Murray’s Hamlet on the Holodeck gave us a realistic assessment of the current state of the art and how we might eventually get there. Sure, we are still arbitrarily far away from the uber virtual experience of the Holodeck. But Second Life, World of Warcraft, and Grand Theft Auto have all broken incredible ground in making a simpler, more feasible version of that experience available today to tens of millions of people.
So, what we can learn from the Genie is how to think about the “perfect” Search service. Imagine for a moment the absolutely perfect search service. Think bigger than natural language search. Think bigger than talking to your computer and getting what you want.
The perfect Search is when you only just barely have to indicate your intention and your search result appears. Somehow, magically, the system just knows what you want and when you are ready to actually act on that desire, the system has already brought your desire to you. No more running to the vending machine to get a soda from an arbitrarily limited selection in fixed volume and vendor-mandated packaging. The system knows you are getting thirsty, knows what you want (not just from history information but even from sensing your current blood-sugar and taste craving) and how you want it, and the moment you commit to getting that soda, it appears at your desk–perhaps even without you knowing exactly which soda you wanted today. All of this done discretely, unobtrusively, privately, and with the utmost discretion so neighbors or co-workers don’t see what you’d rather they don’t. The action, ultimately, is always driven by your committed intention. Not your attention, not some statistically predicted estimate of your desire, but your actual, expressed commitment to realize a particular desire. Express an intention and magically, it is fulfilled.
That’s the Genie.
While it isn’t yet available, bits and pieces of it are becoming available, just as online text MUDs and World of Warcraft are bits and pieces of 30 years working towards the ultimate virtual reality. By placing the committed intention of the user at the core of value creation, at the heart of the system design, I believe the Genie provides an almost the ideal model for conceptualizing the Holy Grail of Search.
Semantic Knowledge Bases
Essentially, I agree with Alex, this is a technology looking for a problem. “Better” data and more “powerful” ways to interact with and reason over that data should provide better results and is, therefore, a Good thing–assuming there are no other costs. Unfortunately, the semantic web has significant transitional and ongoing costs to turn the free-form, anyone-can-post-anything World Wide Web, into a system where participating as a first class of citizen requires using RDF or microformats or some other arcane technology to transform formerly arbitrary scribblings–and marketing and online stores and customer service and media outlets and whatever–into semantically structured information. It requires an imposition of structure that is inherently limiting and counter to the user-centric architecture of the open web.
Nobody wants to pay that cost unless the immediate value to them is obviously much greater. And so far, the value is uncertain and far into the future.
Semantic Search
Alex suggests that because none of the semantic search companies is better than Google that semantic search isn’t the killer app. Well, Google uses a lot of semantics in its Search. Most users just don’t know it. They’ve used Latent Semantic Indexing for years and AdSense is all about wicked smart semantic analysis of web page content for matching ads from the Google ad universe. In fact, one of the more interesting semantic tricks Google does is one you can see for yourself. Try typing “jaguar” (or some other ambiguous term) into Google’s query box.
You’ll find that alternative meanings of “jaguar” all show up in the early results. Jaguar as a car. Jaguar as the cat. Even the Jaguar quantum chemistry package from Schrodinger, which has no reason being in the top ten at Google. Google does this because it knows that from the limited query box, it can’t figure out which Jaguar you really mean. But it also knows that users will filter out the misses and get excited about the hits. They design for the “Ah-hah” moment. As long as one in ten (or so) results matches the user’s intended meaning of Jaguar, then Google gets credit for finding the “right” jaguar. Brilliant.
So, I argue that any search that isn’t semantic is a dinosaur waiting for the undertaker. Maybe it isn’t a killer app as a distinct service, but it is already an integral part of the #1 killer app of the Web, Search.
Social Graph
On this one, Alex fails to explain clearly enough why he doesn’t like it. Any killer app is going to be a “subset” of the entire market. Email isn’t the totality of the Internet, but it is the killer app that first broke down the isolated IT networks and marched like Sherman all the way through to the consumer market to give the sexier World Wide Web a fighting chance at establishing the Internet as much a fundamental part of the civilized world as electricity, running water, and paved roads.
Actually, I think the social graph might be the killer app of the Semantic Web. It doesn’t deliver the full value of the Semantic Web, but it provides such immediate, obvious value for so many people that once the privacy controls are worked out, many many people are going to be surfing the Semantic Web without knowing it as they seamlessly mingle across their social internetwork through the former silos of Facebook, MySpace, Plaxo, and others. If it can be a killer app without people giving it credit, then the Social Graph is definitely a contender.
Shortcuts
This is absolutely illuminating. I like AdaptiveBlue’s product a lot, and others in this category have potential. However, I usually find the disjoint interactions confusing. Shortcuts, by nature, interfere with the “normal” web experience and are inherently intrusive. I happen to have Snap installed on my machine and I’m still surprised and often annoyed when it pops-up “previews” of links I’m doodling my cursor on.
I do that… I doodle mouse and doodle click. I have the same problem at the New York Times’ website, actually. They allow you to look up the meaning of any word on a page just by double-clicking on the word. Problem is, I doodle-click meaninglessly, sort of a virtual twiddling of my thumbs as I browse. And -whoops- I just triggered a new page download I don’t really want. It is a mess.
So, shortcuts have a long way to go to be less intrusive and to find the right “intuitive” connection with the user. Ultimately, I am a huge fan of augmenting the traditional “browse”-based experience of the web, rather than replacing it wholesale. People like the web. They like their services. They like the freedom of going anywhere that supports http and html. And yet, many of those websites don’t have the technical wherewithal to get “semantic”.
BlueOrganizer does a nice job, for example, of connecting IMDB listings of movies with NetFlix so it is easy for you to go from the Internet’s unofficial authority on movies to the leading movie-on-demand service. All without NetFlix or IMDB needing to do anything. That sort of user centrism is critical to the next evolution of the web and it’s the semantics of what is already on the web pages that make that possible. Shortcuts are just one effort to do something with that semantic data. Perhaps as they grow up, they will become more useful to more people.
Closing
Again, despite my initial hopes, I have written WAY too much, which is a pathological flaw I seem to have. Thanks for hanging in there.
My point in responding to Alex’s post is simply this: any killer app needs to start and end with the User. This is so true it has become a software development truism that everybody knows is important, but few know how to translate into their feature development schedule. Technology alone–like Natural Language Understanding–will never be a killer app. Only when someone figures out how to make it electric for users–exciting and immediate and so obviously valuable–can any innovation become a killer app.
With all due respect to the folks who love this term, the Semantic Web is one of those bundling concepts that is about as useful as the term “Electric Appliance.” It is useful in describing a category of product, but completely useless in helping retailers make decisions about what products people are going to buy this season. Until companies move beyond that catch all descriptor into product discussions that connect with what users already understand and want… none of the “semantic” offerings can possibly breakthrough to being a true killer app.